이전에 진행했던 선착순 신청 API 대해 비동기 적용 + lock waitTime 개선을 통해 avg time을 13s에서 2s로 개선했다.
내가 배포를 담당한 프로젝트가 아니다 보니 배포는 이전 EKS 기반 여러 워커 노드가 아닌, 단일 EC2에 단일 컨테이너를 기반으로 테라폼을 통해 간단히 배포했다. (현재 서버 + 알림 서버 + k6 Instance + RDS + DocumentDB + ElastiCache)
- 현/알림 서버 : t3.medium
- k6 서버 : t3.xLarge
- RDS : t3.micro
- ElastiCache : t3.micro
- DocumentDB : t3.medium (선착순 기능에 활용 X)
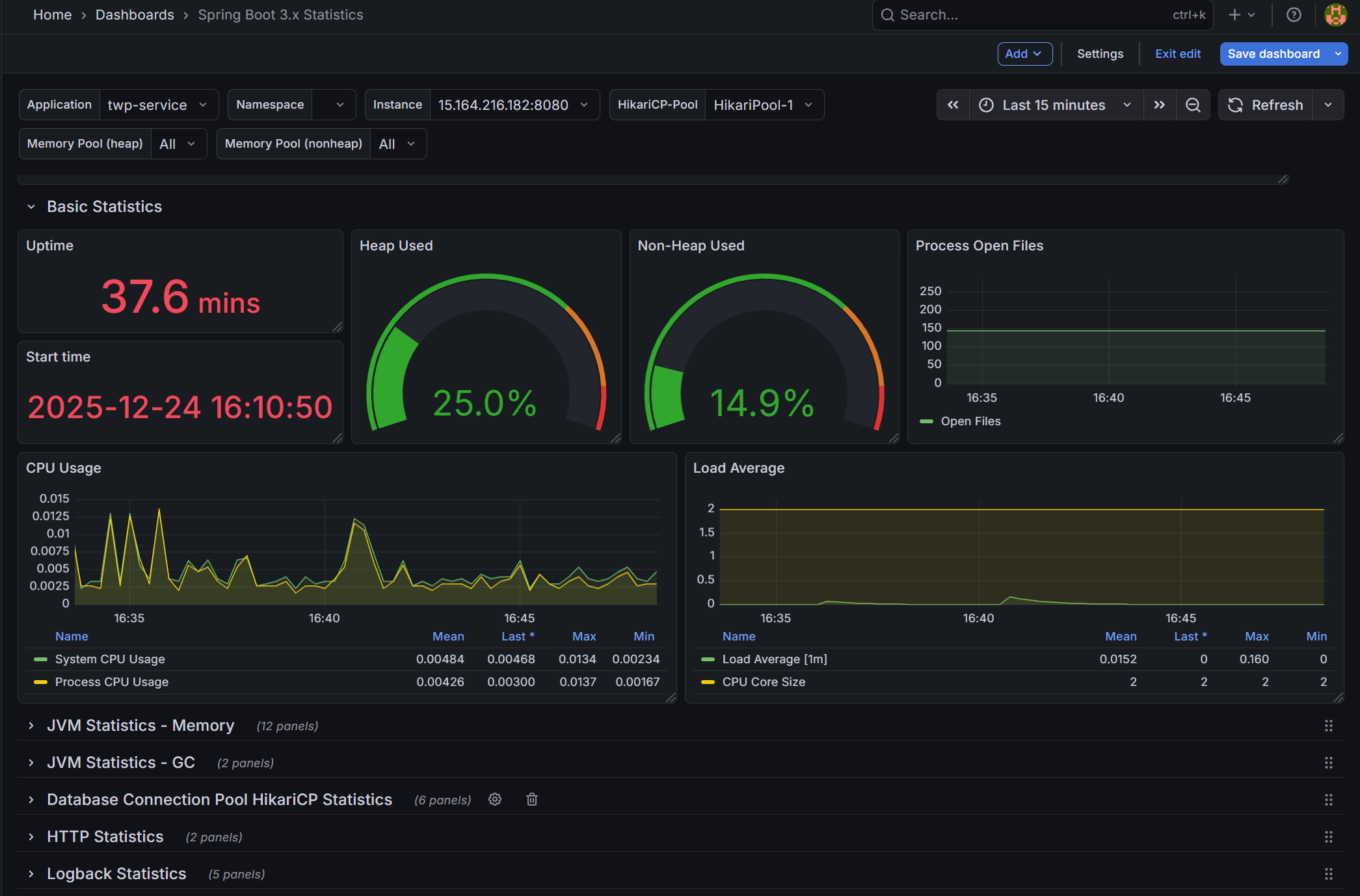
모니터링은 Prometheus + Grafana와 각 DB 내 모니터링 항목을 참조했다. 스프링 서버와 EC2의 상태를 동시에 보고 싶었기에 Node Exporter와 Spring Boot 3.x Statistics 대시보드를 활용하였다. (Prometheus 내 scrape_configs에 :8080/actuator/prometheus와 :9100을 추가해야 대시보드로 볼 수 있다.)
monitoring 위한 ec2 생성 시 사용한 전체 user_data script이다.
user_data = <<-EOF
#!/bin/bash
set -e
hostnamectl --static set-hostname "${var.VpcName}-MONITORING-EC2"
echo 'alias vi=vim' >> /etc/profile
timedatectl set-timezone Asia/Seoul
apt update
apt install -y tree jq git htop unzip curl
# Docker
curl -fsSL https://get.docker.com -o get-docker.sh
sh get-docker.sh
systemctl enable docker
systemctl start docker
sleep 10
################################
# Prometheus
################################
mkdir -p /opt/prometheus
cat <<PROM > /opt/prometheus/prometheus.yml
global:
scrape_interval: 15s
scrape_configs:
- job_name: "twp-spring-app"
metrics_path: "/actuator/prometheus"
static_configs:
- targets:
- "${aws_instance.twp_instance.public_ip}:8080"
- job_name: "twp-node-exporter"
static_configs:
- targets:
- "${aws_instance.twp_instance.public_ip}:9100"
- job_name: "user-spring-app"
metrics_path: "/actuator/prometheus"
static_configs:
- targets:
- "${aws_instance.user_instance.public_ip}:8080"
- job_name: "user-node-exporter"
static_configs:
- targets:
- "${aws_instance.user_instance.public_ip}:9100"
PROM
################################
# Grafana Provisioning
################################
mkdir -p /opt/grafana/provisioning/datasources
mkdir -p /opt/grafana/provisioning/dashboards
mkdir -p /opt/grafana/dashboards
# Datasource
cat <<DS > /opt/grafana/provisioning/datasources/prometheus.yaml
apiVersion: 1
datasources:
- name: Prometheus
type: prometheus
access: proxy
url: http://192.168.4.100:9090
isDefault: true
DS
# Dashboard provisioning
cat <<DBP > /opt/grafana/provisioning/dashboards/dashboards.yaml
apiVersion: 1
providers:
- name: default
orgId: 1
folder: ''
type: file
disableDeletion: false
editable: true
options:
path: /var/lib/grafana/dashboards
DBP
################################
# Dashboards (1860 / 19004)
################################
curl -s https://grafana.com/api/dashboards/1860/revisions/37/download \
-o /opt/grafana/dashboards/node-exporter.json
################################
# Run Containers
################################
docker run -d \
--name prometheus \
--restart unless-stopped \
-p 9090:9090 \
-v /opt/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml \
prom/prometheus
docker run -d \
--name grafana \
--restart unless-stopped \
-p 3000:3000 \
-v /opt/grafana/provisioning:/etc/grafana/provisioning \
-v /opt/grafana/dashboards:/var/lib/grafana/dashboards \
grafana/grafana
EOF
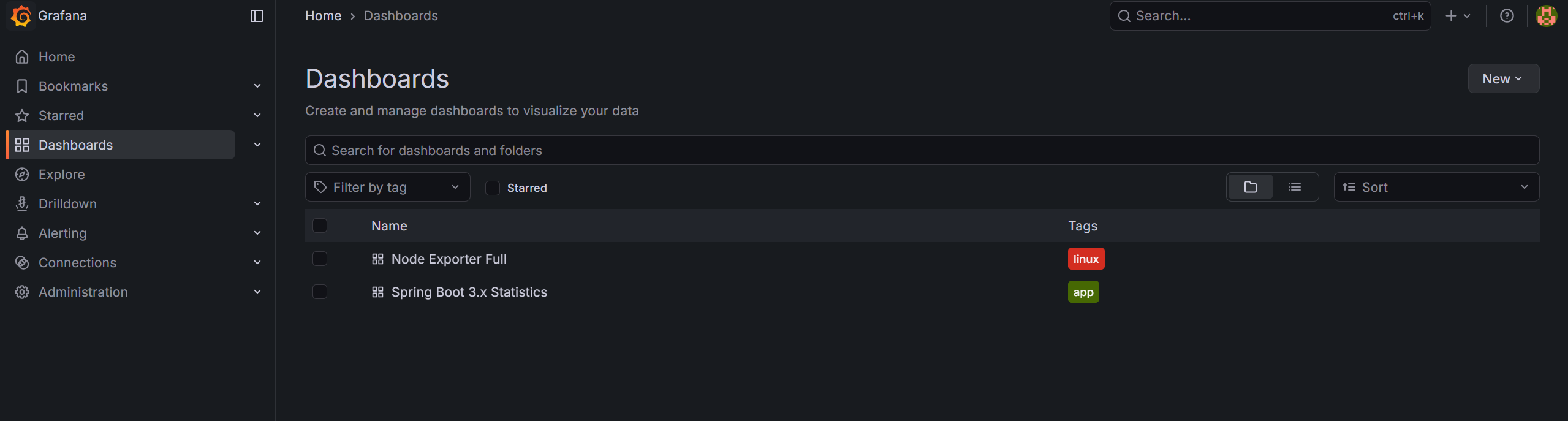
상단의 대시보드를 쓰고 싶다면 Home > Dashboards > 우상단 New의 2번째 칸에 Node Exporter Full은 1860, Spring Boot 3.x Statistics는 19004를 입력하면 된다.


개선 전 코드이다. 당시 인프라는 Kakao Cloud 내에 K8s를 통해 여러 서버가 배치되었기에, Redisson을 통해 락을 구현하였다.
@Component
@RequiredArgsConstructor
public class PartyApplyFacade {
private final RedissonClient redissonClient;
private final PartyService partyService;
public void applyParty(CustomOAuth2User oauth2User, Long partyId) {
RLock lock = redissonClient.getLock(partyId.toString());
boolean isLocked = false;
try {
isLocked = lock.tryLock(10, TimeUnit.SECONDS);
if (isLocked) {
partyService.applyPartyFCFS(oauth2User, partyId);
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
if (isLocked && lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
}
public void applyPartyFCFS(CustomOAuth2User oauth2User, Long partyId) {
Party party = partyRepository.findById(partyId)
.orElseThrow(() -> new NotFoundException("직관팟이 존재하지 않습니다!"));
Long userId = validateApplyCondition(oauth2User, partyId, party);
party.increaseCurrentParticipants();
partyJoinRepository.save(PartyJoin.create(userId, party, PartyJoinRequestStatus.ACCEPT, null));
notificationFeignClient.notifyParty(PartyNotificationEvent.joined(
party.getId(), party.getTitle(), party.getWriterId(), userId
));
}
초반에 성능을 개선하려 할 때에는 위처럼 FeignClient를 기반으로 알림 요청을 날리는 것보다, 비동기 + EventListener를 통해 request를 다른 thread에 위임하고, 동시에 비즈니스 로직과 알림 요청을 분리해 개선하는 것으로 방향을 잡았다.

이를 위해 AsyncConfig와 EventListener를 작성하고, applyPartyFCFS() 에서 event를 publish하는 걸로 방향을 바꿨다. 동시에 DB에 반영된 후 알림 요청을 보내고 싶어서 @TransactionalEventListener(phase = TransactionPhase.AFTER_COMMIT) 을 활용했다. (COMMIT 후 이벤트 처리)
@Configuration
@EnableAsync
public class AsyncConfig {
@Value("${thread-pool.noti.core-size}")
private int coreSize;
@Value("${thread-pool.noti.max-size}")
private int maxSize;
@Value("${thread-pool.noti.queue-capacity}")
private int queueCapacity;
@Bean(name = "notificationAsyncExecutor")
public Executor notificationAsyncExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(coreSize);
executor.setMaxPoolSize(maxSize);
executor.setQueueCapacity(queueCapacity);
executor.setThreadNamePrefix("noti-async-");
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.AbortPolicy());
executor.initialize();
return executor;
}
}
public void applyPartyFCFS(CustomOAuth2User oauth2User, Long partyId) {
Party party = partyRepository.findById(partyId)
.orElseThrow(() -> new NotFoundException("직관팟이 존재하지 않습니다!"));
Long userId = validateApplyCondition(oauth2User, partyId, party);
party.increaseCurrentParticipants();
partyJoinRepository.save(PartyJoin.create(userId, party, PartyJoinRequestStatus.ACCEPT, null));
eventPublisher.publishEvent(
PartyNotificationEvent.joined(
party.getId(), party.getTitle(), party.getWriterId(), userId
)
);
}
@Component
@RequiredArgsConstructor
public class PartyNotificationEventListener {
private final NotificationFeignClient notificationFeignClient;
@Async("notificationAsyncExecutor")
@TransactionalEventListener(phase = TransactionPhase.AFTER_COMMIT)
public void handle (PartyNotificationEvent event) {
notificationFeignClient.notifyParty(event);
}
}
사용한 k6 script는 다음과 같다. 선착순 API이므로 짧은 시간 (10s) 내에 진행되도록 했고, 250 vu/10s 시나리오로 부하 테스트 진행 시 Node Exporter 대시보드 내 CPU 사용량이 약 6~70% 정도로 CPU 병목이 되지 않는 선에서 진행하기 위해 선정했다.
constant-vus는 사용자가 일정하게 유지되면서 요청을 보내게 하기 위해 정했다.
정상 case 시 201, 사용자 초과되어 신청 불가 시 409가 반환되도록 되어 있기에 각 횟수를 측정하고 있다
import http from 'k6/http';
import { Counter, Rate } from 'k6/metrics';
/**
* Custom Metrics
*/
export const successCount = new Counter('fcfs_success_count');
export const conflictCount = new Counter('fcfs_conflict_count');
export const errorCount = new Counter('fcfs_error_count');
// 성공률 (201만 성공으로 봄)
export const successRate = new Rate('fcfs_success_rate');
export const options = {
scenarios: {
fcfs_test: {
executor: 'constant-vus',
vus: 250,
duration: '10s',
},
},
};
export default function () {
const url = 'http://13.209.99.31:8080/party/1/apply/fcfs';
const params = {
headers: {
'Cookie':'Access=eyJhbGciOiJIUzI1NiJ9.eyJqdGkiOiJjOTZmZDgxYi1mNDhkLTQyNjYtOTNjNS0xYzY4ODA3MTk4N2IiLCJzdWIiOiIyIiwicm9sZSI6IlVTRVIiLCJhZ2UiOjEwLCJnZW5kZXIiOiJNQUxFIiwidHlwZSI6ImFjY2VzcyIsImlhdCI6MTc2NTg2NDg1MCwiZXhwIjo3ODEzODY0ODUwfQ.my9zaplonm5ivE4HFy4_ML2hk0XBjGqCgzwIbVdYKJw',
'Accept': '*/*',
'Connection': 'keep-alive',
},
};
const res = http.post(url, null, params);
/**
* 응답 코드 분기
*/
if (res.status === 201) {
successCount.add(1);
successRate.add(true);
} else if (res.status === 409) {
conflictCount.add(1);
successRate.add(false); // 성공은 아님, 하지만 실패도 아님
} else {
errorCount.add(1);
successRate.add(false);
}
}
초기 feignClient만 사용했을 때의 결과이다. 부하 테스트는 약 15:15분 경 진행되었다. avg 시간으로 약 11초 소모되었다.

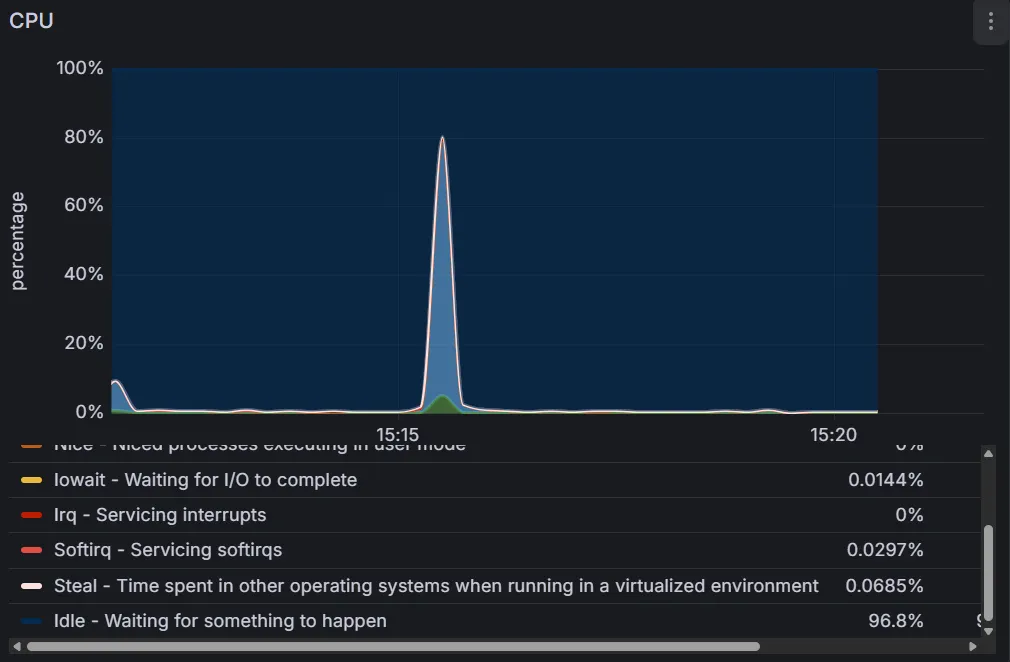
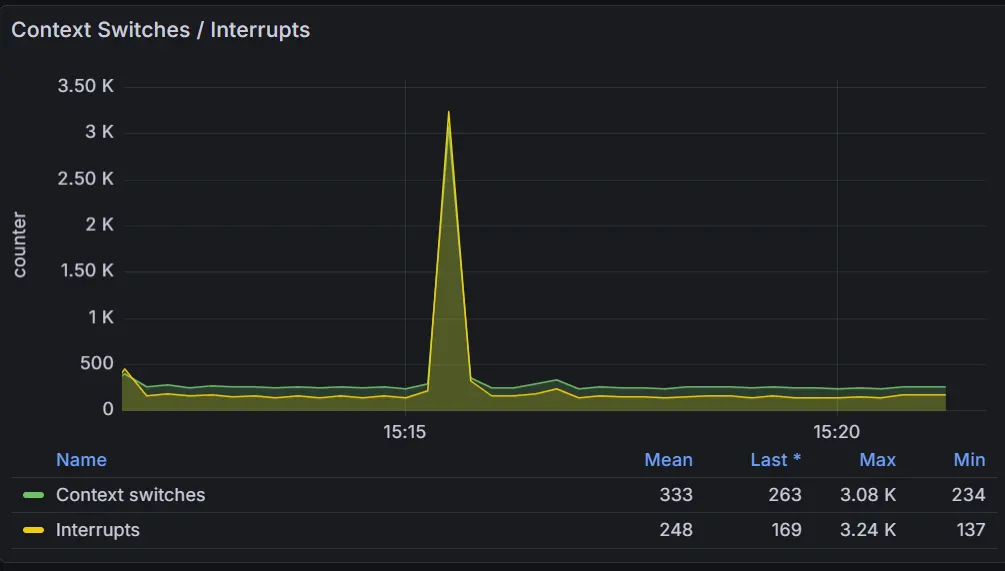

아래는 RDS의 모니터링 결과다.
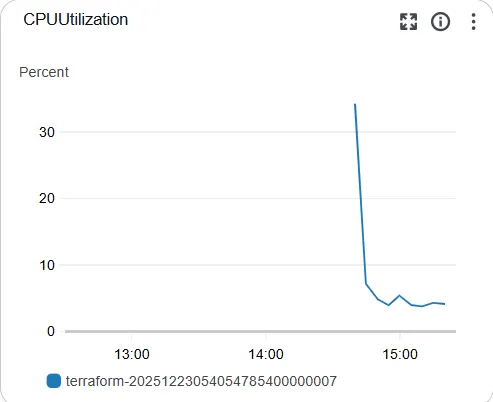

아래는 ElastiCache의 결과이다.

두 DB 모니터링 결과 크게 부하가 가해지지 않는 걸로 보인다.
이후에는 비동기 기반으로 진행한 결과이다. CORE_SIZE는 아래 공식을 참고해서 22에서 일의 자리를 버려 20으로 정했다.
MAX_SIZE와 QUEUE_CAPACITY는 많은 동시 요청을 처리하고, 동시에 빠른 포화로 새로운 스레드가 빨리 생성되도록 하기 위해 각각 100/10으로 정했다.
Number of threads = Number of Available Cores * (1 + Wait time / Service time)
= 2 (t3.medium의 코어 수) * (1 + 50 / 5) = 22
(외부 서버 대한 요청이 있어서 Wait time을 보다 길게 잡았다.)



추가로 thread pool에 대한 설정은 GPT의 추천대로 task가 대기하도록 하기 위해 CORE=4, MAX=8, QUEUE=200으로 설정했을 때, 결과는 다음과 같았다. 초기 스레드 풀 설정 시에는 avg가 9.92s였지만, 11.58s로 크게 오른 걸 볼 수 있다.
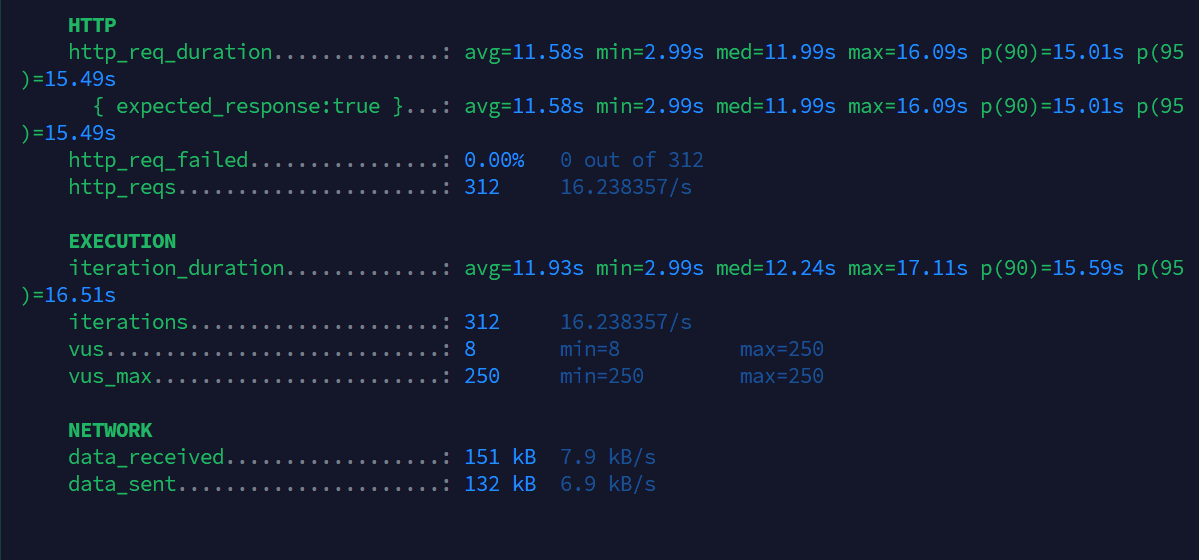
비동기 적용으로 avg 시간이 9초로 조금 줄어들기는 했지만, 크게 줄어든 상태는 아니었다. 관련해서 스레드 풀 패널 내 notificationAsyncExecutor의 active_threads를 확인해보니 여유로운 것을 알 수 있다.

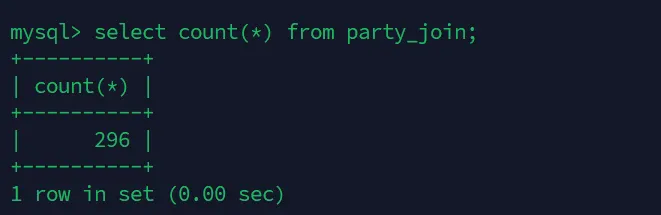
각 부하 테스트 이후, DB에는 제대로 데이터가 들어갔나 RDS에 접속하니 FeignClient 테스트 중 데이터가 추가된 개수가 달랐다. 상단에서 http_reqs가 331이었고, 각 API 요청에 대해 party_join 대해 데이터가 하나씩 추가되지만 실제 추가된 수는 151개였다.

이에 대해 비동기 시에도 데이터 추가 개수가 다른지 확인하기 위해 추가 부하 테스트를 진행하였고, 그 결과는 296개, 320개로
달랐다.

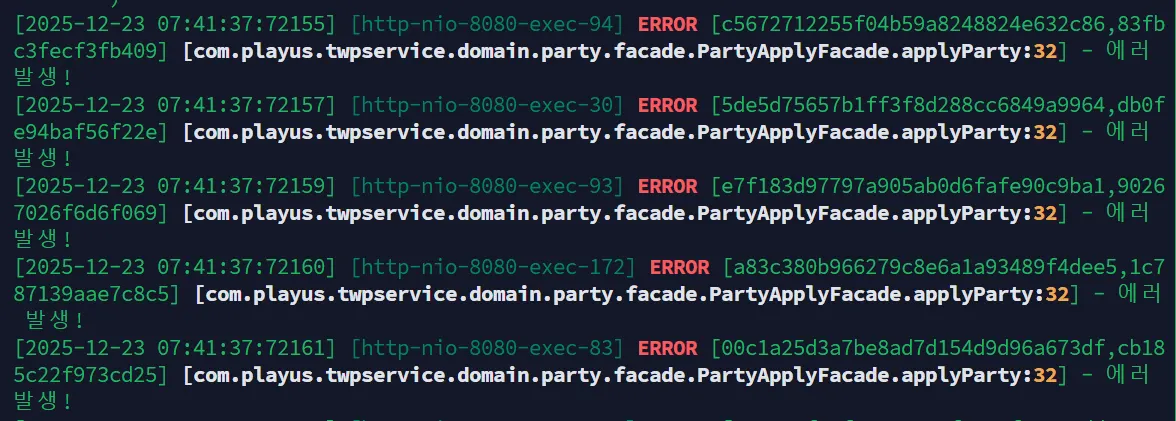
원인을 파악하기 위해 Lock 관련 코드를 다시 확인해보니, 락을 획득하지 못할 경우에는 따로 예외 처리 등이 없는 것을 알 수 있었다! Lock을 획득하지 못해 생기는 문제가 맞는지 락 획득 실패 시 임시로 log.error()가 호출되도록 하였다.
@Component
@RequiredArgsConstructor
public class PartyApplyFacade {
private final RedissonClient redissonClient;
private final PartyService partyService;
public void applyParty(CustomOAuth2User oauth2User, Long partyId) {
RLock lock = redissonClient.getLock(partyId.toString());
boolean isLocked = false;
try {
isLocked = lock.tryLock(10, TimeUnit.SECONDS);
if (isLocked) {
partyService.applyPartyFCFS(oauth2User, partyId);
}
else {
log.error('에러 발생');
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
if (isLocked && lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
}
그 결과, 락을 획득하지 못해 에러 로그가 출력되는 것을 알 수 있었고, 부하 테스트 재시도 시 success_count와 party_join 내 record의 개수가 같은 것을 확인할 수 있었다.

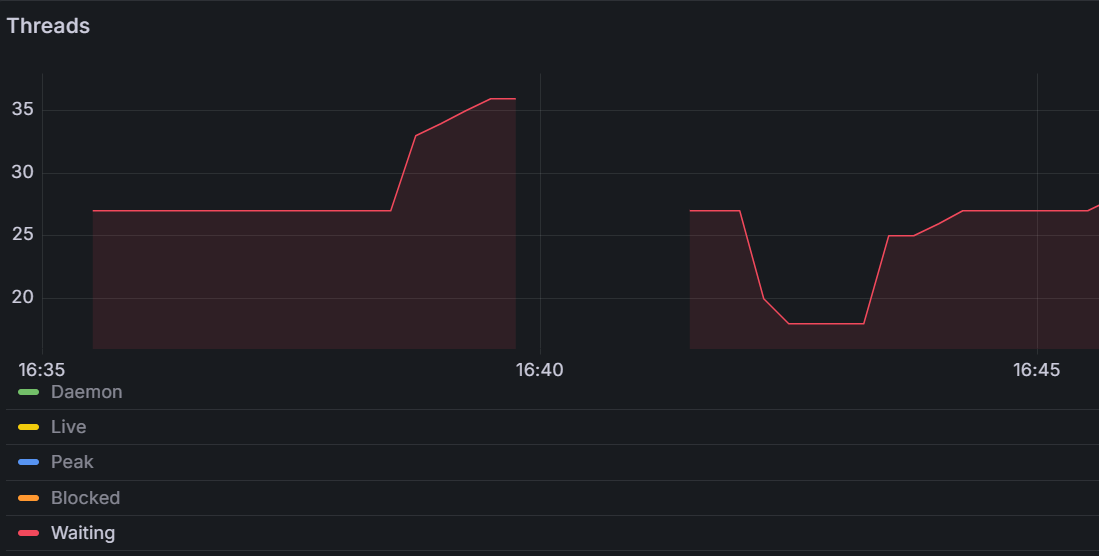
관련 이슈 해결 후 Threads 패널로 가 보니, 부하 테스트 이전과 달리 Waiting threads의 수가 증가한 것을 확인할 수 있었다. 이를 기반으로 긴 waitTime 때문에 스레드가 불필요하게 대기 상태로 머물어 Latency가 길어진 것이 아닐까 생각해, 락 획득 시도 시간을 줄여보기로 했다.

tryLockTime은 Postman을 통해 로컬 > API 사용 시 약 70~100ms 정도가 나와 기본값을 100으로 정했다. (LockAcquireFailException throw 시 409가 반환되도록 했다.)
@Component
@RequiredArgsConstructor
public class PartyApplyFacade {
@Value("${lock.try-timeout.apply-party:100}")
private int tryLockTime;
private final RedissonClient redissonClient;
private final PartyService partyService;
public void applyParty(CustomOAuth2User oauth2User, Long partyId) {
RLock lock = redissonClient.getLock(partyId.toString());
boolean isLocked = false;
try {
isLocked = lock.tryLock(tryLockTime, TimeUnit.MILLISECONDS);
if (isLocked) {
partyService.applyPartyFCFS(oauth2User, partyId);
}
else {
throw new LockAcquireFailException("서버가 혼잡합니다. 잠시 후 시도해주세요!");
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
if (isLocked && lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
}
변경 후 다시 부하 테스트를 시도해본 결과, avg가 11초에서 2초대로 크게 줄은 것을 확인할 수 있다. 이에 더해 http_reqs도 초반 FeignClient의 300대에 비해 현재는 Latency가 줄어 1000까지 늘어난 것을 볼 수 있다.

부하 테스트 재시도 후, waiting thread의 수도 줄어든 걸 확인할 수 잇엇다! (중간 docker rm 실행으로 그래프가 비어잇는 상태)
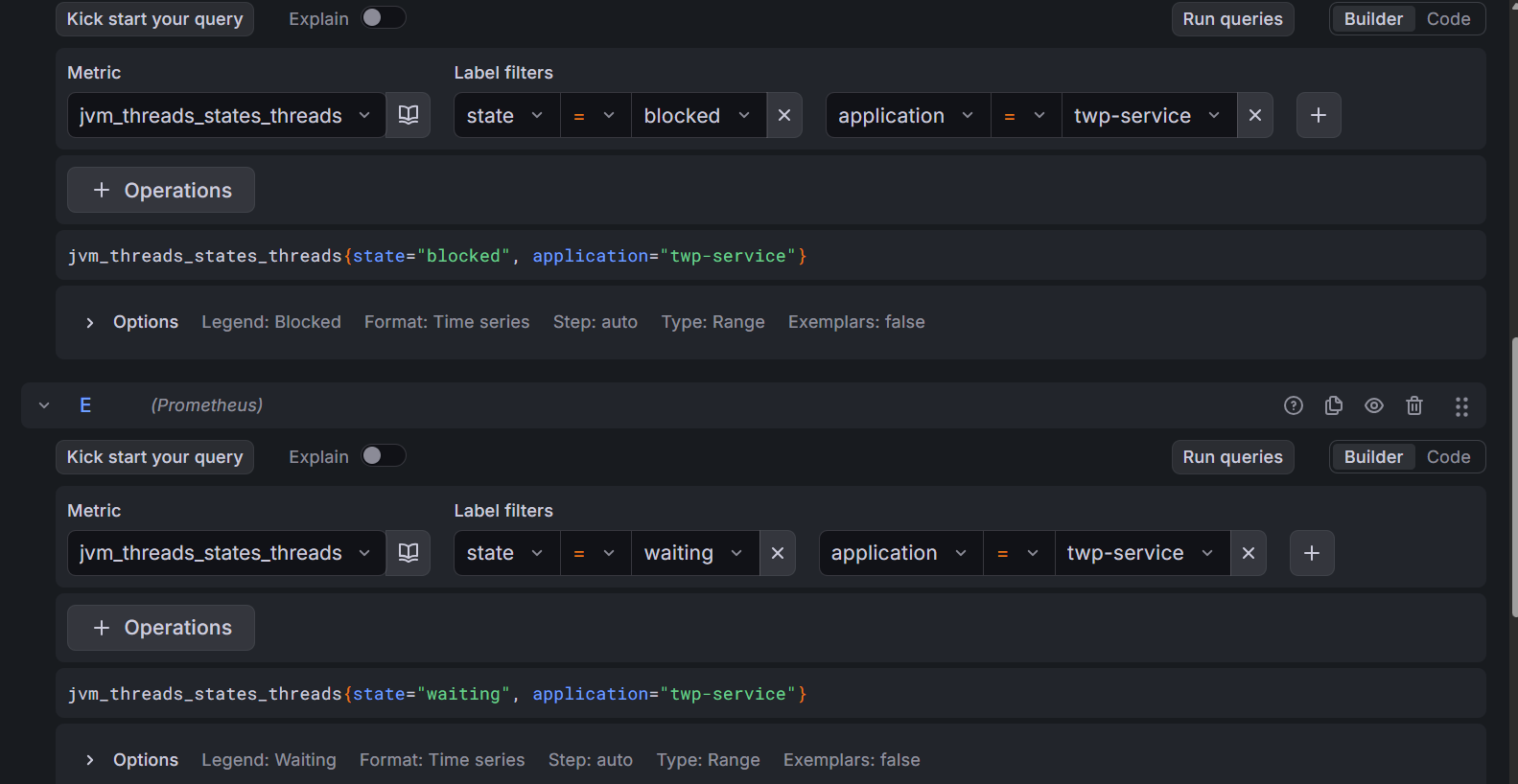
cf> Waiting 및 Blocked thread는 기본 Threads 패널에서 제공하지 않아, 다음과 같이 추가했다. Legend (범례) 변경으로 각 그래프 명칭? 을 바꿀 수 잇다.
'프로젝트 > PlayUs' 카테고리의 다른 글
| 12. SentryConfig, SwaggerConfig 적용 (0) | 2025.06.16 |
|---|---|
| 11. Elasticsearch 를 이용한 제목 기반 검색 기능 구현 (0) | 2025.06.16 |
| 10. env 파일 적용 (0) | 2025.06.16 |
| 9. Redisson 을 이용한 분산 락 구현 (0) | 2025.06.16 |
| 8. Spring Data MongoDB에서의 Soft Delete + @Query 사용하면서 나너무많은일이잇엇어 (0) | 2025.05.17 |